12.3 支持向量机和核¶
| 原文 | The Elements of Statistical Learning |
|---|---|
| 翻译 | szcf-weiya |
| 发布 | 2016-09-30 |
| 更新 | 2025-12-30 |
| 状态 | Done |
至今所描述的支持向量机是在输入特征空间中寻找线性边界.和其他的线性方法一样,我们可以用基展开的方式来增大特征空间,从而让这一过程更灵活,如多项式或者样条(第 5 章).一般地,在增长的空间的线性边界能够达到更好的训练类别分割的效果,进而转换为原始空间中的非线性边界.一旦选定基函数 $h_m(x),m=1,\ldots,M$,则该过程和之前一样.我们采用输入特征 $h(x_i)=(h_1(x_i),h_2(x_i),\ldots,h_M(x_i)),i=1,\ldots,N$ 拟合 SV 分类器,并且得到(非线性)函数 $\hat f(x)=h(x)^T\hat\beta+\hat\beta_0$.分类器和之前一样,为 $\hat G(x)=\sign(\hat f(x))$.
支持向量机 (support vector machine) 分类器是这个想法的拓展,其中增长空间的维数允许非常大,有时甚至可以是无限维的.计算似乎会变得难以承受.而且似乎当有了充分多的基函数,数据会变得可分,同时也会发生过拟合.我们首先介绍 SVM 怎样处理这些问题.接着我们将看到实际中 SVM 分类器是采用特定的准则和正则化形式来解决函数拟合问题,而且这是包含第 5 章的光滑样条的更大类别的问题的一部分.读者可能希望参照 5.8 节,它提供了背景材料并且与接下来的两节会有一定的重复.
用于分类的 SVM¶
Recall
我们可以用一种特殊的方式来表示优化问题 \eqref{12.9} 和它的解,这种方式只通过内积来涉及输入特征.我们对这个变换后的特征向量 $h(x_i)$ 直接进行这样的操作.我们将看到对于特定选择的 $h$,这些内积可以很方便地进行计算.
Lagrange 对偶函数 \eqref{12.13} 有如下形式:
从 \eqref{12.10} 中我们看到解函数 $f(x)$ 可以写成
和之前一样,给定 $\alpha_i$,当 $0 < \alpha_i < C$ 时,$\beta_0$ 可以通过对任意(或所有)$x_i$ 求解 $y_if(x_i)=1$ 来确定.
所以 \eqref{12.19} 和 \eqref{12.20} 仅仅通过内积涉及 $h(x)$.实际上,我们根本不需要明确变换关系 $h(x)$,而仅仅要求知道在转换后的空间中计算内积的核函数
$K$ 应该是一个对称的(半)正定函数:见5.8.1节.
在 SVM 中有三种流行的 $K$ 可以选择
考虑含有两个输入变量 $X_1$ 和 $X_2$ 的特征空间,以及 2 阶的多项式核.则
则 $M=6$,而且如果我们选择 $h_1(X)=1,h_2(X)=\sqrt{2}X_1,h_3(X)=\sqrt{2}X_2,h_4(X)=X_1^2,h_5(X)=X_2^2$,以及 $h_6(X)=\sqrt{2}X_1X_2$,则$K(X,X’)=\langle h(X),h(X’)\rangle$.
从 \eqref{12.20} 我们可以看出该解可以写成
在增广的特征空间中,参数 $C$ 的角色更加清晰,因为在这里经常会存在完美的分割.较大的 $C$ 会抑制任何正的 $\xi_i$,并且得到在原始特征空间中过拟合的弯弯曲曲的边界;较小的 $C$ 值会鼓励较小的 $\Vert\beta\Vert$,反过来会导致 $f(x)$ 以及边界更加地光滑.图 12.3 显示了应用到第 2 章中的混合模型的两个支持向量机.两种情形下的正则化参数都是为了实现更好的测试误差.对该例子而言,径向基得到类似贝叶斯最优边界;与图 2.5 进行比较.
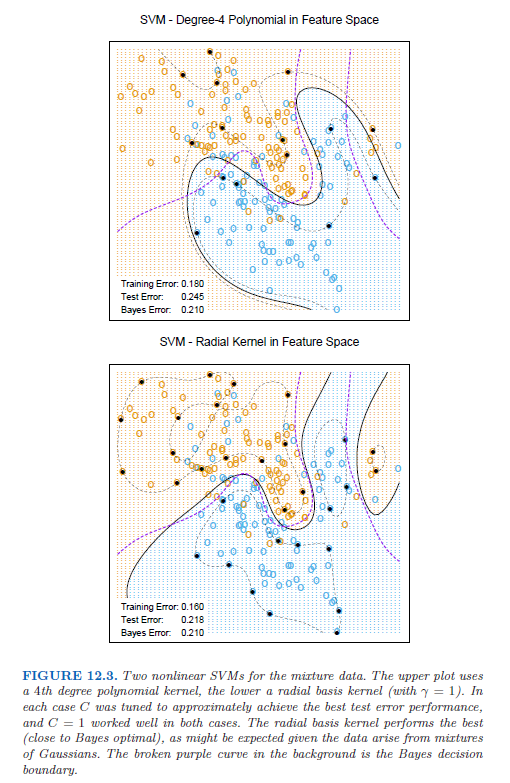
在支持向量的早期研究中,有断言称,支持向量机的核性质是唯一的,并且允许对维数灾难进行巧妙地处理.
这些断言都不是正确的,我们将在下一节详细讨论这些问题.
weiya 注:SVM with Gaussian kernel
知乎上看到这样一个问题,支持向量机高斯核方法? - 知乎,觉得很有意思,具体探索过程见Issue 77: SVM with Gaussian kernel.
SVM 作为惩罚的方法¶
对于 $f(x)=h(x)^T\beta+\beta_0$,考虑下列的优化问题
其中下标“$+$”表示正的部分.上式是“损失+惩罚”的形式,这在函数估计中是个很熟悉的范例.可以很简单地证明当 $\lambda=1/C$ 时,\eqref{12.25} 的解与 \eqref{12.8} 的解相同(练习 12.1).
Recall
weiya 注:Ex. 12.1
已解决.详细证明过程见Issue 78: Ex. 12.1
对“hinge”损失函数 $L(y,f)=[1-yf]_+$ 的检验表明,它用于二类别分类是很合理的.图 12.4 将之与逻辑斯蒂回归的 对数似然损失(log-likelihood loss) 进行比较,以及平方误差损失及其的变种.负对数似然或者二项偏差和 SVM 损失有着类似的尾分布,对 margin 中的点赋予零惩罚,对在错误一侧的点赋予线性惩罚.另一方面,平方误差给出了平方惩罚,在各自margin中的点对模型也有很强的影响.squared hinge损失$L(y,f)=[1-yf]_+^2$类似平方损失,但它对于各自margin中的点惩罚为0.它在左尾中平方增长,而且对于误分类的观测点,没有hinge或者偏差稳健.最近 Rosset and Zhu (2007)1 提出 squared hinge 损失的“Huberized”版本,在 $yf=-1$ 处将其平滑转换为了线性损失.
weiya 注:Huberized squared hinge loss
文献Rosset and Zhu (2007)1中提出的 Huberized squared hinge loss 的表述更一般,可以在任意 $t < 1$ 处进行 Huberized,文献截图如下:
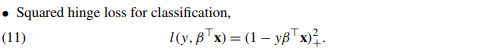

我们可以在总体水平上用估计量来区分这些损失函数.我们考虑最小化 $\E L(Y,f(x)$.

表 12.1 总结了这些结果.然而 hinge 损失估计了分类器 $G(x)$ 本身,而其他的都估计类别后验概率的某个变换.“Huberized” square hinge损失有着与逻辑斯蒂回归相同的吸引人的性质(光滑的损失函数,估计概率),以及 SVM 的 hinge 损失的良好性质(支撑点).
式 \eqref{12.25} 将 SVM 看成正则化的函数估计问题,其中线性展开 $f(x)=\beta_0+h(x)^T\beta$ 的系数向 0 收缩(除了常值).如果 $h(x)$ 表示有相同的序结构(比如按粗糙程度排序)的 分层基 (hierarchical basis),如果在向量 $h$ 中更粗糙的元素 $h_j$ 有更小的范数,则均一化收缩是更有意义的.
Question
什么是 hierarchical basis?探索过程见Issues 79: hierarchical basis
除了平方误差,表 12.1 中所有的损失函数,都称之为 “margin maximizing loss-functions”(Rosset et al., 2004b2).这意味着如果数据是可分的,则当 $\lambda\rightarrow 0$ 时,$\hat\beta_\lambda$ 的极限定义为最优分离超平面.
weiya 注:原书脚注
对于可分数据的逻辑斯蒂回归,$\hat\beta_\lambda$ 发散,但是 $\hat\beta_\lambda/\Vert\hat\beta_\lambda\Vert$ 收敛到最优分离超平面.(Why?)
函数估计和再生核¶
这里我们用 再生核希尔伯特空间 (reproducing kernel Hilbert space, RKHS) 中的函数估计来描述 SVM,其中有许多的核性质.这里的内容在 5.8 节有详细讨论.这里给出支持向量分类器的另一个视角,并且帮助理清它如何工作.
假设基 $h$ 来自与正定核 $K$ 的(可能是有限的)特征展开,
weiya 注:Mercer’s theorem
\eqref{12.26} 的分解由 Mercer’s theorem 保证
 图片来源: Wiki: Mercer’s theorem
图片来源: Wiki: Mercer’s theorem
并且 $h_m(x)=\sqrt{\delta_m}\phi_m(x)$.则当$\theta_m=\sqrt{\delta_m}\beta_m$,我们可以把 \eqref{12.25} 写成
Recall
现在 \eqref{12.27} 与 5.8 节中的 \eqref{5.49} 形式相同,并且再生希尔伯特空间的理论保证了形如下式的有限维的解
特别地,我们看到存在等价的优化准则【5.8.2节的式 \eqref{5.67};也可以参见 Wahba et al. (2000)3】
其中 $\K$ 是所有成对训练特征的核的赋值(练习 12.2).
weiya 注:Ex. 12.2
已解决,详见 Issue 80: Ex. 12.2,欢迎交流讨论。
这些模型非常一般,举个例子,包含第 5 和第 9 章中讨论的整个光滑样条族,可加和交叉样条模型,更多细节参见 Wahba (1990)4 和 Hastie and Tibshirani (1990)5.它们可以更一般地表示为
其中 $\cal H$ 是 函数的结构空间 (structured space of functions),并且 $J(f)$ 是在该空间上合适的正则器.举个例子,假设$\cal H$是可加函数 $f(x)=\sum_{j=1}^pf_j(x_j)$,并且$J(f)=\sum_j\int\{f^{\prime\prime}_j(x_j)\}^2dx_j$.则 \eqref{12.30} 的解为可加三次样条,并且有核表示 $K(x,x’)=\sum_{j=1}^pK_j(x_j,x_j’)$.每个 $K_j$ 是关于 $x_j$ 的合适的单变量光滑样条的核(Wahba, 1990)4.
反过来,这个讨论也表明,举个例子,任意 \eqref{12.22} 中提到的核都可以和凸损失函数一起使用,并且将会得到形如 \eqref{12.28} 的有限维表示.图 12.5 采用和图 12.3 同样的核函数,除了采用二项对数似然作为损失函数.因此拟合函数是 log-odds 的估计
或者反过来,我们得到类别概率的估计
这些拟合的模型在形状和表现效果上都非常相似.5.8节给出了例子以及更多的细节.
对于 SVM 也是一样,$N$ 个 $\alpha_i$ 中的一部分可以为 0(非支持点).在图 12.3 的两个例子中,这些比例分别为 $42\%$ 和 $45\%$.这是准则 \eqref{12.25} 的第一部分分段线性的本质.(在训练数据上)类别重叠越少,这个比例越大.降低 $\lambda$ 一般会降低重叠(允许更灵活的$f$).较少的支持点意味着 $\hat f(x)$ 可以更快地进行赋值,这在查找时很重要.当然,过分降低重叠会导致泛化能力太差.
SVM 和维数灾难¶
在这一节,我们回答“SVMs是否存在维数灾难”的问题。注意到在展开式 \eqref{12.23} 中,我们不允许在幂和乘积的空间中有完全一般的内积.举个例子,所有形如 $2X_jX_j’$ 赋予相同的权重,并且核不能自适应地集中到某子空间中.
Note
基于下文的比较,特别是高阶多项式与低阶多项式,这里应当是指 SVM 中的核不允许退化,比如某个参数为 0,并不具有像 MARS 等方法的自适应能力。
如果特征的数量 $p$ 很大,但是类别分类仅仅发生在 $X_1$ 和 $X_2$ 张成的子空间,这个核不会简单地找到其结构并且需要在很多维度下搜寻.必须将子空间的信息考虑进核中,也就是,忽略 除了 前两个的输入.如果有信息能够得到先验,大多数统计学习会变得很简单.自适应方法的主要目标是发现类似的结构.
我们用一个例子来支持上面的陈述.我们在两个类别中产生 100 个观测值.第一类有 4 个标准正态独立特征 $X_1,X_2,X_3,X_4$.第二类也有四个标准正态独立特征,但是条件为 $9\le \sum X_j^2\le 16$.这是个相对简单的问题.同时考虑第二个更难的问题,用 6 个标准高斯噪声特征作为增广特征.因此在四维子空间中第二类完全包围了第一类,类似橘子皮包围着橘子.该问题的贝叶斯误差率为 0.029(不考虑维数).我们产生 1000 个测试观测量来比较不同的过程.在有无噪声特征的情况下,平均测试误差在 50 个模拟中得到,如表 12.2 所示.
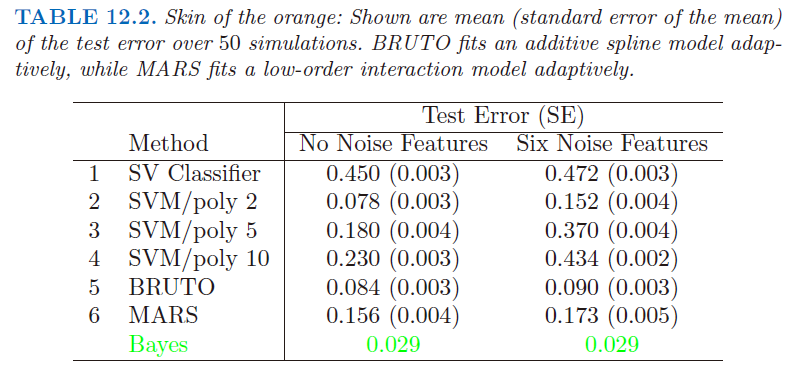
表中第一行在原特征空间中使用支持向量分类器.第 2 到第 4 行表示使用 2,5 和 10 维多项式核的支持向量机.对于所有的支持向量过程,我们选择代价参数 $C$ 来最小化测试误差,使得对这个方法尽可能公平.第 5 行采用可加模型的 BRUTO 算法(Hastie and Tibshirani (1990)),通过最小二乘对 $(-1,+1)$ 响应变量拟合可加样条模型.第 6 行采用 MARS(多变量自适应回归样条)允许任意阶的交叉影响,在第 9 章中有介绍;同样地,其与 SVM/poly 10 进行比较.BRUTO 和 MARS 算法均有能力忽略冗余变量.第 5 和第 6 行并不采用测试误差来选择光滑参数.
Info
笔记模拟:Tab. 12.2重现了表 12.2 的结果.
在原始特征空间中,超平面不能分离类别,而且支持向量分类器(第一行)表现很差.多项式支持向量机在测试误差率方面取得显著改善,但同时也被6个噪声特征严重影响.这对核的选择非常敏感:二阶多项式核(第2行)表现最好,因为真实的判别边界就是二阶多项式.然而,高阶多项式(第3和第4行)表现很差.BRUTO 表现得很好,因为其边界是可加的.BRUTO 和 MARS 自适应得很好:因为噪声的存在,所以它们的表现不会退化太大.
SVM 分类器的路径算法¶
SVM 分类器的正则化参数是代价参数 $C$,或者 \eqref{12.25} 中 $\lambda$ 的倒数.通常用法是将 $C$ 设得比较高,这通常会过拟合分类器.
图 12.6 展示了混合数据的测试误差作为 $C$ 的函数的变化图像,其中采用不同的径向核参数 $\gamma$.
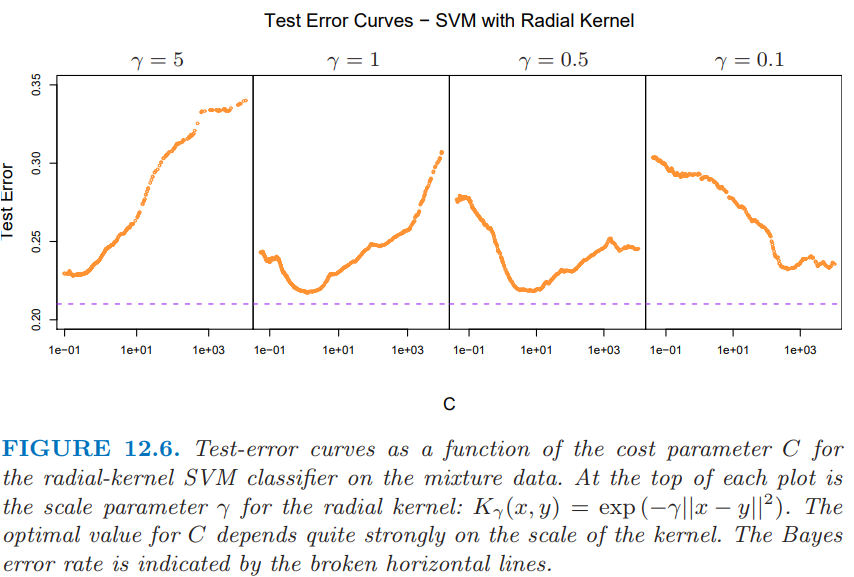
当 $\gamma=5$ 时(narrow peaked kernels),需要最重的正则化(即较小 $C$).当 $\gamma=1$时(图 12.3 所用的值),需要中等大小的 $C$.显然在这些情形中,我们需要确定合适的 $C$,或许可以通过交叉验证实现.这里我们描述一种路径算法(受3.8节的启发),可以用来有效拟合改变 $C$ 得到的 SVM 模型序列.
使用 \eqref{12.25} 的损失+惩罚的形式以及图 12.4 中的损失函数是很方便的.这可以得到在给定 $\lambda$ 处 $\beta$ 的解:
其中 $\alpha_i$ 仍然是 Lagrange 乘子,但是在这种情形下它们都在 [0, 1] 中取值.
图 12.7 说明了这个过程.
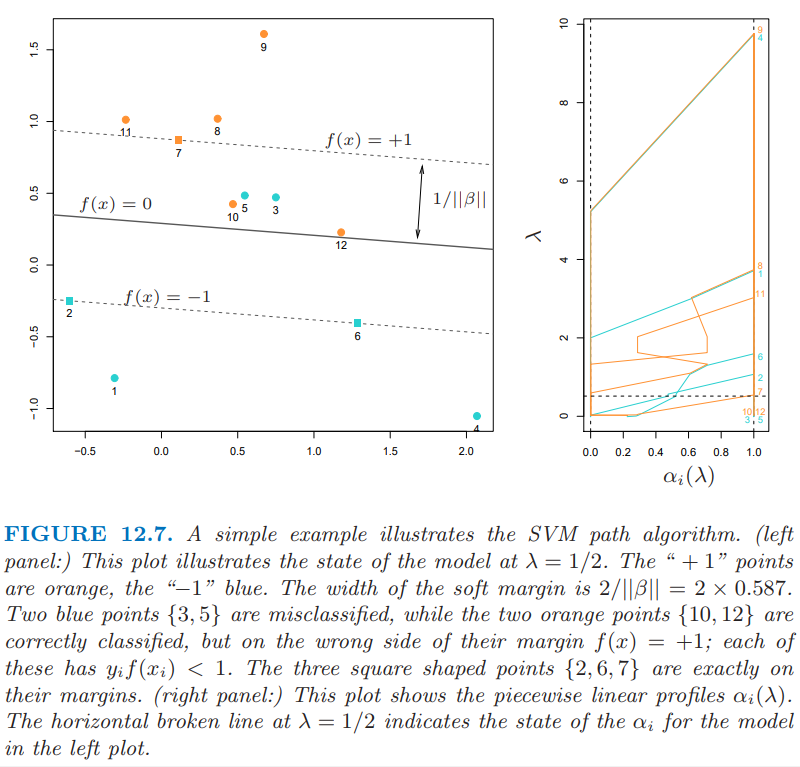
可以看到 KKT 优化条件表明点 $(x_i,y_i)$ 落在三个不同的区域中:
- 正确分类且落在各自 margins 之外.它们满足 $y_if(x_i) > 1$,并且 Lagrange 乘子满足 $\alpha_i=0$.比如图中橘黄色的点 8,9和 11,以及蓝色点 1 和 4.
- 正好落在各自 margin 上,满足 $y_if(x_i)=1$,其中 Lagrange 乘子 $\alpha_i\in [0, 1]$.比如图中橘黄色点7,以及蓝色点2和6.
- 在 margin 之内,满足 $y_if(x_i) < 1$,且 $\alpha_i=1$.比如蓝色点3和5,以及橘黄色点10和12.
weiya注:KKT条件及三种划分
这在上一节也有讨论,参见12.2 支持向量分类器.唯一区别在于这里$\alpha_i$的分界点为1,而上一节为$C$.但这很好理解,因为用$\frac{1}{\lambda}$作为参数,相对于(12.8),除以了$C$,更多细节可以参见Issue 78: Ex. 12.1
路径算法的思想如下.选择较大的 $\lambda$ 来初始化,则 margin 的宽度 $1/\Vert \beta_\lambda\Vert$ 较宽,所有点都在各自margin 中且 $\alpha_i=1$.当 $\lambda$ 减小时,$\frac{1}{\Vert\beta_\lambda\Vert}$ 减小,则 margin 变窄.有些点会各自margin 内移到 margin 之外,并且它们 $\alpha_i$ 从 1 变为 0.由 $\alpha_i(\lambda)$ 的连续性,这些点在转移的过程中会在 margin 上停留(linger).由 \eqref{12.33},我们看到 $\alpha_i=1$ 的点对 $\beta(\lambda)$ 的贡献是固定的,而那些 $\alpha_i=0$ 的点没有贡献.所以当 $\lambda$ 减小时,改变量是那些在 margin 边界上的点,它们满足 $\alpha_i\in[0,1]$.因为这些点都满足 $y_if(x_i)=1$,这一小部分的线性等式的解决定了 $\alpha_i(\lambda)$ 以及由其导致的 $\beta(\lambda)$ 在这些转移过程中的变化.对于 $\alpha_i(\lambda)$ 的每个值,这些解是分段线性路径.断点仅发生在穿过 margin 的时候.图 12.7 的右面板展示了 $\alpha_i(\lambda)$ 在左面板例子中的图象.
尽管我们只介绍了线性 SVMs 的方法,但是对于非线性模型,想法完全一样,只需要将 \eqref{12.33} 换成
细节可以在 Hastie et al. (2004)6中找到.CRAN上R包svmpath可以用来拟合这些模型.
用于回归的支持向量机¶
在这一节,我们将要展示 SVMs 如何用于定量响应变量的回归问题,方法继承了 SVM 分类器的某些性质.我们首先讨论线性回归模型
接下来处理非线性的推广情形.为了估计 $\beta$,我们考虑下式的最小化
其中
这是一种“$\epsilon$-insensitive”的误差度量,它忽略了小于 $\epsilon$ 的误差(图 12.8 的左图).
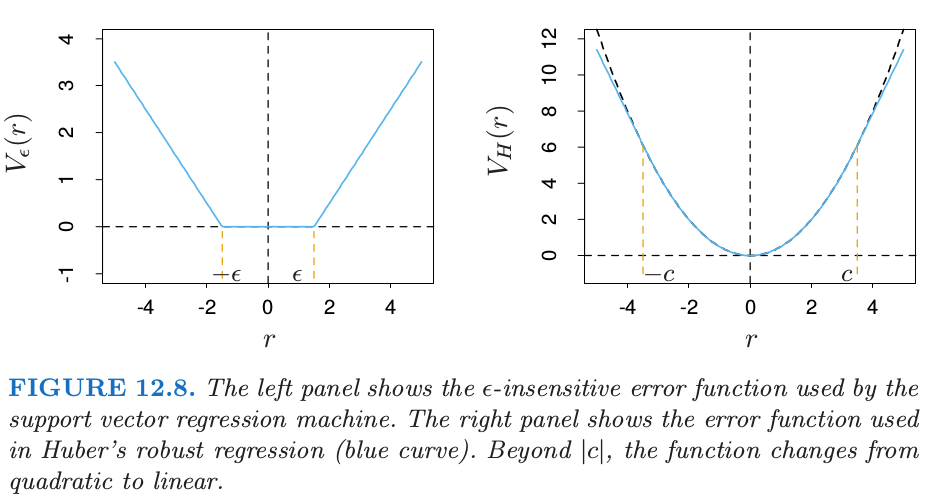
这一点类似支持向量机在分类问题中的设定,处于判别边界正确一侧的点以及远离边界的点在优化过程中都被忽略了.在回归中,这些“low error”的点是残差较小的点.
将这个误差度量与统计中鲁棒回归中采用的误差度量比较是很有趣的.图 12.8 的右图展示了鲁棒回归中误差度量的最受欢迎的形式(Huber (1964)7):
当绝对残差大于预先给定的某个常值 $c$ 时,函数将观测的贡献从二次降至一次.这使得拟合对离群点更加不敏感.支持向量误差衡量 \eqref{12.37} 也有线性尾 (tail)(大于 $\epsilon$),但是除此之外,它压缩了小偏差情形下观测点的贡献.
如果 $\hat\beta,\; \hat\beta_0$ 是 $H$ 的最小值点,则解函数有如下形式
其中 $\hat\alpha_i,\; \hat\alpha_i^*$ 是正的,且是下列的二次规划问题的解
约束条件如下
考虑到这些约束的本质,一般仅仅有部分的解 $(\hat \alpha_i^*-\hat\alpha_i)$ 非零, 并且对应的数据称为支持向量.和分类问题中的设定一样,解仅仅通过内积 $\langle x_i, x_{i’}\rangle$ 来关联输入的数据.因此我们可以通过定义合适的内积将这个方法推广到高维空间,举个例子,采用 \eqref{12.22} 中定义的任意一个.
注意到参数 $\epsilon$ 和 $\lambda$ 与准则 \eqref{12.36} 有关.它们似乎扮演不同的角色,$\epsilon$ 是损失函数 $V_{\epsilon}$ 的参数,这和 $c$ 是 $V_H$ 的参数一样.注意到 $V_{\epsilon}$ 和 $V_H$ 都依赖 $y$ 的尺度,因此依赖于 $r$.如果我们对响应变量进行缩放(也因此需要用 $V_H(r/\sigma)$ 和 $V_\epsilon(r/\sigma)$),则我们可能考虑采用预先设定的 $c$ 和 $\epsilon$(对于高斯情形,取 $c=1.345$ 能达到 $95\%$ 的有效度).$\lambda$ 是更传统的正则参数,并且可以通过交叉验证来估计.
回归和核¶
正如 12.3.3 节讨论的一样,SVM 的核性质不唯一.假设我们考虑用基函数 $\{h_m(x)\},m=1,2,\ldots,M$ 近似的回归函数:
为了估计 $\beta$ 和 $\beta_0$,对于一般的误差度量$V(r)$,我们需要最小化
对于任意选择的 $V(r)$,解 $\hat f(x)=\sum\hat\beta_mh_m(x)+\hat\beta_0$ 有如下形式
其中 $K(x,y)=\sum_{m=1}^Mh_m(x)h_m(y)$.注意到这与径向基函数展开和正则化估计的形式一样,它们在第 5 章和第 6 章有讨论.
具体地(For concreteness),考虑$V(r)=r^2$的情形.令 $\H$ 为 $N\times M$ 的基矩阵,第 $im$ 个元素为 $h_m(x_i)$,并且假设 $M > N$ 较大.为了简单起见,假设 $\beta_0 = 0$,或者将常数包含进 $h$ 中;练习12.3给出了另一种方式.
通过最小化带惩罚的最小二乘准则来估计$\beta$
解为
其中$\hat\beta$由下式确定
从这里看,我们似乎需要在转换后的空间中对内积的 $M\times M$ 的矩阵进行赋值.然而,我们可以乘以 $\H$ 得到
$N\times N$ 的矩阵 $\H\H^T$ 包含了成对观测 $i,i’$ 间的内积;也就是,内积核$\{\H\H^T\}_{i.i’}=K(x,x_{i’})$的赋值.易证 \eqref{12.44} 正是这种情形,在任意点 $x$ 的预测值满足
其中 $\hat\alpha=(\H\H^T+\lambda\I)^{-1}\y$.和 SVM 中一样,我们不需要确定或者计算函数集 $h_1(x), h_2(x),\ldots,h_M(x)$.仅仅需要在 $N$ 个训练点中,对每个 $i,i’$ 计算内积核 $K(x_i,x_{i’})$,以及预测时对预测点 $x$ 计算内积核.小心选择 $h_m(x)$(比如特殊的、容易计算的核$K$ $K$ 时$\H\H^T$ 计算量为 $N^2/2$,而不是直接计算时的 $N^2M$.
然而,注意到,这个性质取决于惩罚项中平方范数 $\Vert\beta\Vert^2$ 的选择.举个例子,对于可能会得到更好模型的 $L_1$ 范数 $\vert\beta\vert$,这个性质并不满足.
讨论¶
SVM可以拓展到多类别问题,本质上是求解多个两个类别的问题.对每个成对类别建立分类器,最终的分类器是起主要作用的分类器(Kressel, 19998; Friedman, 19969; Hastie and Tibshirani, 199810).另外,可以采用合适核的多项损失函数,就像 12.3.3 节一样.SVMs在许多监督学习和非监督学习的问题中都有应用.在本文的写作时间,经验表明它在许多实际学习问题中表现得非常好.
最后,我们提出 SVM 和 结构风险最小化 (structural risk minimization, SRM) (7.9 节)间的联系.
假设训练点(或者它们的基函数展开)在半径为 $R$ 的球体中,并且令 \eqref{12.2} 中的 $G(x)=\sign[f(x)]=\sign[\beta^Tx+\beta_0]$.
Recall
则可以证明类别函数 ${G(x),\Vert\beta\Vert\le A}$ 的 VC 维 $h$ 满足
如果 $f(x)$ 分离训练数据,对于 $\Vert \beta\Vert\le A$ 是最优的,则在训练集上至少有概率 $1-\eta$ 满足
支持向量分类器是第一个可以得到 VC 维的有效界的实际学习过程,因此可以应用 SRM.然而,在推导的时候,计算过程依赖特征的观测值,称为“balls are put around the data points”.因此在严格意义上,类别的 VC 复杂度在知道特征之前不是预先固定的.
正则参数 $C$ 控制了分类器的 VC 维的上界.遵循 SRM 的范式,我们可以通过最小化测试误差 \eqref{12.51} 的上界来选择 $C$.然而,并不清楚它与通过交叉验证来选 $C$ 有什么优势.
-
Rosset, S. and Zhu, J. (2007). Piecewise linear regularized solution paths, Annals of Statistics 35(3): 1012–1030. 下载 ↩↩
-
Rosset, S., Zhu, J. and Hastie, T. (2004b). Margin maximizing loss functions, in S. Thrun, L. Saul and B. Schölkopf (eds), Advances in Neural Information Processing Systems 16, MIT Press, Cambridge, MA. ↩
-
Wahba, G., Lin, Y. and Zhang, H. (2000). GACV for support vector machines, in A. Smola, P. Bartlett, B. Sch¨olkopf and D. Schuurmans (eds), Advances in Large Margin Classifiers, MIT Press, Cambridge, MA., pp. 297–311. ↩
-
Wahba, G. (1990). Spline Models for Observational Data, SIAM, Philadelphia. ↩↩
-
Hastie, T. and Herman, A. (1990). An analysis of gestational age, neonatal size and neonatal death using nonparametric logistic regression, Journal of Clinical Epidemiology 43: 1179–90. ↩
-
Hastie, T., Rosset, S., Tibshirani, R. and Zhu, J. (2004). The entire regularization path for the support vector machine, Journal of Machine Learning Research 5: 1391–1415. ↩
-
Huber, P. (1964). Robust estimation of a location parameter, Annals of Mathematical Statistics 53: 73–101. ↩
-
Kressel, U. (1999). Pairwise classification and support vector machines, in B. Sch¨olkopf, C. Burges and A. Smola (eds), Advances in Kernel Methods - Support Vector Learning, MIT Press, Cambridge, MA.,pp. 255–268. ↩
-
Friedman, J. (1996). Another approach to polychotomous classification, Technical report, Stanford University ↩
-
Hastie, T. and Tibshirani, R. (1998). Classification by pairwise coupling, Annals of Statistics 26(2): 451–471. ↩