4.3 线性判别分析¶
| 原文 | The Elements of Statistical Learning |
|---|---|
| 翻译 | szcf-weiya |
| 发布 | 2016-12-16 |
| 更新 | 2025-12-30 |
分类的判别理论(2.4节)告诉我们,我们需要知道的是最优分类的类别后验概率 $\Pr(G\mid X)$.假设 $f_k(x)$ 是类别 $G=k$ 中 $X$ 的类别条件密度,并令 $\pi_k$ 为类别 $k$ 的先验概率,满足 $\sum_{k=1}^K\pi_k=1$.简单地应用一下贝叶斯定理得到
我们看到就 判别能力(ability to classify) 而言,知道 $f_k(x)$ 几乎等价于知道概率 $\Pr(G=k\mid X=x)$.
许多方法是基于类别密度的模型:
- 采用高斯密度的线性和二次判别分析
- 更加灵活的混合的高斯密度,允许非线性判别边界(6.8 节)
- 对每个类别密度进行一般的非参数密度估计,允许最大的灵活性(6.6.2 节)
- 朴素贝叶斯(Naive Bayes) 模型是上个情形的变种,并且假设每个类密度是边缘密度的乘积,这也就是,假设输入在每一类中都是条件独立的(6.6.3节)
假设我们每个类别密度用多元高斯分布来建模
假设类别有相同的协方差矩阵 $\Sigma_k=\Sigma\;\forall k$ 时,会导出 线性判别分析 (Linear Discriminant Analysis, LDA).在比较两个类别 $k$ 和 $\ell$ 时,比较 log-ratio 就足够了,而且我们可以看到
weiya 注
如果 $D$ 为对称矩阵,则
这是个关于 $x$ 的线性等式.协方差矩阵相等时会消除了正规化因子,以及指数中的二次项.这个线性的 log-odds 函数表明类别 $k$ 和类别 $\ell$ 的判别边界为 $p$ 维超平面——$\Pr(G=k\mid X=x)=\Pr(G=\ell\mid X=x)$ 的集合,这关于 $x$ 是线性的.对于任意类别对也是成立的,所以所有的判别边界都是线性的.如果我们把 $\IR^p$ 分成不同区域,记为类别 1,类别 2 等等,这些区域会被超平面所分离.图 4.5(左图)显示了有三个类别且 $p=2$ 的假想的例子.这里数据是从 3 个协方差矩阵相等的高斯分布中产生的.我们已经在图中画出了对应 95% 概率密度的等高图,以及三个类别的形心.注意到判别边界不是连接两个形心的垂直平分线.如果协方差矩阵 $\Sigma$ 是 $\sigma^2\mathbf I$,且类别的先验概率相等.从 \eqref{4.9} 我们可以看出线性判别函数为
这是判别规则的等价描述,$G(x)=\mathrm{argmax}_k \delta_k(x)$.
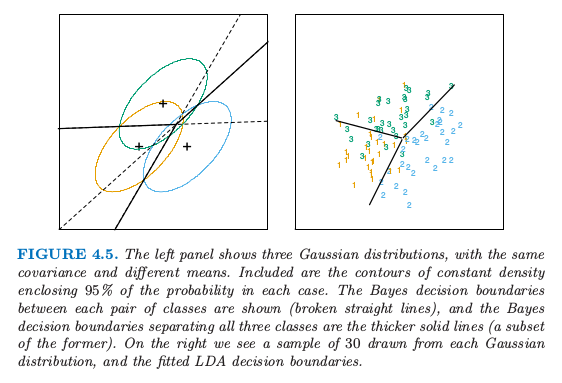
图 4.5. 左图显示了三个高斯分布,有相同的协方差和不同的均值.图中画出了在包含每个类别 95% 可能性的等高线.两两类别之间的贝叶斯判别边界用虚线显示,并且贝叶斯判别边界将所有的三个类别分隔开用实线表示出来(前者的一个子集).右图我们看到有来自每个高斯分布的 30 个样本点以及画出了拟合后的 LDA 判别边界.
weiya 注:重现图 4.5
详细过程见模拟:Fig. 4.5.
实际应用中我们不知道高斯分布的参数,我们需要用我们的训练数据去估计它们:
- $\hat \pi_k=N_k/N$,其中 $N_k$ 是第 $k$ 类观测值的个数;
- $\hat\mu_k=\sum_{g_i=k}x_i/N_k$;
- $\hat{\boldsymbol\Sigma}=\sum_{k=1}^K\sum_{g_i=k}(x_i-\hat\mu_k)(x_i-\hat\mu_k)^T/(N-K)$.
图 4.5(右图)显示了基于从 3 个高斯分布中取出的大小为 30 的样本集得到的判别边界的估计,图 4.1 是另外一个例子,但是那里类别不是高斯分布.
weiya 注:Recall
两个类别的情况下在线性判别分析和线性最小二乘之间有一个简单的对应,如 \eqref{4.5} 所示.如果满足下面条件则 LDA 分类规则分给第二类
否则分为第一类.假设我们将两个类别分别编码为 $+1$ 和 $-1$.可以简单地证明得出最小二乘的系数向量与 \eqref{4.11} 式给出的 LDA 方向成比例(练习 4.2).【实际上,这种对应关系对于任意的编码都会有,见练习 4.2】.然而除了 $N_1=N_2$ 的情形,截距不同因此得到的判别边界不一样.
weiya 注:Ex. 4.2
已解决,详见 Issue 108: Ex. 4.2.
因为通过最小二乘得到的 LDA 方向不需要对特征做高斯分布的假设,它的应用可以不局限于高斯分布的数据.然而,\eqref{4.11} 式给出的特定的截距和分离点确实需要高斯分布的数据.因此对于给定的数据集凭经验地选择分割点最小化训练误差是有意义的.这也是我们在实际中发现效果很好,但是在理论中没有提到的原因.
多于两个类别的情形时,LDA 与类别指示矩阵的线性回归不是一样的,而且它避免了跟这个方法有关的掩藏问题 (Hastie et al., 19941). 回归与 LDA 之间的对应可以通过在 12.5 节中讨论的最优评分来建立.
回到一般的判别问题 \eqref{4.8},如果没有假设 $\boldsymbol\Sigma_k$ 相等,则 \eqref{4.9} 中的抵消不会发生;特别地,关于 $x$ 的平方项保留了下来.于是我们得到了平方判别函数 QDA 每个 类别对 (pair of classes) $k$ 和 $\ell$ 的判别边界由二次等式来描述 $\{x:\delta_k(x)=\delta_\ell(x)\}$.
图 4.6 显示了一个例子(图 4.1),这三个类别都是混合高斯分布(6.8 节),并且判别边界由关于 $x$ 的二次函数近似给出.这里我们描述两种拟合这些判别边界的方式.右图使用这里描述的 QDA,而左图是在增广的五维二次多项式空间中使用 LDA.两者之间的差别很小,QDA 是最好的方式,LDA 方法是更方便的替换.
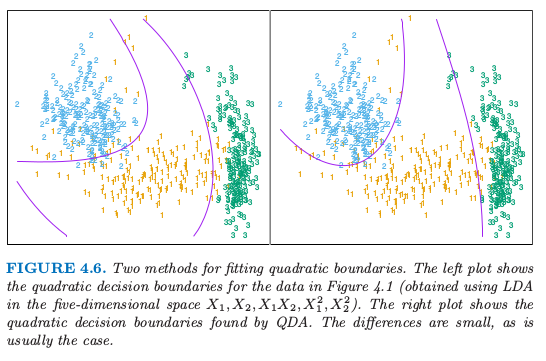
图 4.6. 拟合二次边界的两种方法.左图显示了图 4.1 的二次判别边界(在五维空间 $X_1,X_2,X_1X_2,X_1^2,X_2^2$ 中运用 LDA 得到).右图显示了通过 QDA 寻找到的二次判别边界.两者差别很小,通常也是这种情况.
QDA 的估计类似 LDA 的估计,除了协方差矩阵必须要按每一类来估计.当 $p$ 很大这意味着系数有显著性的增长.因为判别边界是系数密度的函数,参数的个数必须要考虑.对于 LDA,似乎有 $(K-1)\times(p+1)$ 个参数,因为我们仅仅需要判别函数之间的不同 $\delta_k(x)-\delta_K(x)$,其中 $K$ 是一些预先选好的类别(这里我们已经选了最后一类),每个差异需要 $p+1$ 个参数.对于 QDA 类似地,我们会有 $(K-1)\times \{p(p+3)/2+1\}$ 个参数.LDA 和 QDA 在非常大以及离散的数据集的分类上面表现得很好.举个例子,在 STATLOG 项目中 (Michie et al. 19943) LDA 在 7 个数据集(总共 22 个数据集)中的表现排前三名,QDA 在四个数据集中排前三名,对于 10 个数据集两种方法的其中一种排前三名.两种方法都被广泛运用,整本书集中讨论 LDA.在各种外来方法风靡一时的今天,我们总是会有两种简单的方法可以使用.为什么 LDA 和 QDA 有那么好的效果?原因不可能是数据近似服从高斯分布,对于 LDA 协方差矩阵也不可能近似相等.很可能的一个原因是数据仅仅可以支持简单的判别边界比如线性和二次,并且通过高斯模型给出的估计是稳定的,这是一个偏差与方差之间的权衡——我们可以忍受线性判别边界的偏差因为它可以通过用比其它方法更低的方差来弥补.这个论点对于 QDA 更是不可想象,因为它自身有许多的参数,尽管或许比非参估计的参数要少.
正则化判别分析 (RDA)¶
Friedman (1989)2 提出 LDA 和 QDA 之间的一个权衡,使得 QDA 的协方差阵向 LDA 中的共同协方差阵收缩.这些方法非常类似岭回归.正则化协方差矩阵有如下形式 其中,$\hat\Sigma$ 是和 LDA 一样用的联合协方差矩阵.这里 $\alpha\in[0,1]$ 允许在 LDA 和 QDA 之间连续变化的模型,而且需要指定.实际中,$\alpha$ 可以基于在验证数据的表现上进行选择,或者通过交叉验证.
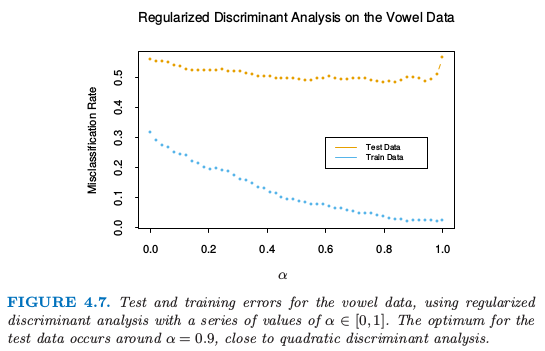
图 4.7. 对元音数据应用一系列 $\alpha\in[0,1]$ 的正则化判别分析的测试和训练误差.测试数据的最优点发生在 $\alpha=0.9$ 附近,离二次判别分析很相近.
图 4.7 显示了将 正则化判别分析 (Regularized Discriminant Analysis, RDA) 运用到元音数据的结果.训练和测试误差都随着 $\alpha$ 的增大获得了改善,尽管在 $\alpha=0.9$ 后测试误差急剧上升.训练和测试误差最大的区别部分因为在小数量的个体上有很多重复观测,在训练和测试集上是不同的.
类似的修改使得 $\hat\Sigma$ 向着标量协方差收缩,对于 $\gamma\in[0,1]$,有 用 $\hat{\boldsymbol\Sigma}(\gamma)$ 替换掉 \eqref{4.13} 的 $\hat{\boldsymbol\Sigma}$ 导出了一个更加一般的协方差阵族 $\hat{\boldsymbol\Sigma}(\alpha,\gamma)$,这是由一对参数来表示的.
在 12 章,我们将讨论 LDA 的另一种正则化版本,当数据来自数字化的相似的信号和图像时,这种方法会更加地合适.在这些情形下特征是高维的且相关的,LDA 系数可以通过正则化在原始信号域变得光滑和稀疏.这导出了更好的一般化并且对于这些系数有着简单的解释.在第 18 章中我们也处理非常高维的问题,举个例子如微阵列研究中基因表达测量的特征.那里方法集中在 \eqref{4.14} 中 $\gamma=0$ 的情形,以及其它 LDA 的正则化版本.
LDA 的计算¶
作为下一主题的铺垫,我们简单地岔开去讨论 LDA,特别是 QDA 的计算.这些计算可以通过对角化 $\hat\ssigma$ 或 $\hat\ssigma_k$ 来简化.对于后者,假设我们对每一个计算特征值分解 $\hat\ssigma_k=\mathbf U_k\mathbf D_k\mathbf U_k^T$,其中 $\mathbf U_k$ 是 $p\times p$ 的正交矩阵,$\mathbf D_k$ 是正的特征值 $d_{k\ell}$ 组成的对角矩阵.则 $\delta_k(x)$ \eqref{4.12} 的组成成分是
- $(x-\hat\mu_k)^T\hat\ssigma_k^{-1}(x-\hat\mu_k)=[\U_k^T(x-\hat\mu_k)]^T\mathbf D_k^{-1}[\mathbf U_k^T(x-\hat\mu_k)]$
- $\log\vert \hat\ssigma_k\vert=\sum_{\ell}\log d_{k\ell}$
按照上面列出的计算步骤,LDA 分类器可以通过下面的步骤来实现
- 对数据关于协方差矩阵 $\hat{\boldsymbol\Sigma}$ 球面化:$X^*\leftarrow \mathbf D^{-\frac{1}{2}}\mathbf U^T X$,其中 $\hat{\boldsymbol\Sigma}=\mathbf U\mathbf D\mathbf U^T$.$X^*$ 的共同协方差矩阵变为单位阵.
- 考虑类别先验概率 $\pi_k$ 的影响,在变换后的空间里面分到最近的类别形心.
降维线性判别分析¶
至此我们已经讨论了限制为高斯分类器的 LDA.它受欢迎的部分原因是因为额外的限制使得我们可以看到数据在低维空间中富含信息的投影.
在 $p$ 维输入空间的 $K$ 个形心位于维数 $\le K-1$ 的超平面子空间中,如果 $p$ 比 $K$ 大很多,维数上会有显著的降低.更多地,在确定最近的形心时,我们可以忽略到子空间的垂直距离,因为它们对每个类的作用同样大.因此我们可能仅仅需要将数据 $X^*$ 投射到形心张成的子空间 $H_{K-1}$ 中,并且在子空间内比较距离.因此在 LDA 中存在一个基础维数的降低,换句话说就是,我们仅仅需要考虑在维数至多为 $K-1$ 的子空间的数据.如果 $K=3$,举个例子,这允许我们可以在二维图中观察数据,对类别进行颜色编码.这样做我们不会丢失任何 LDA 分类需要的信息.
weiya 注
更直观的解释如下图
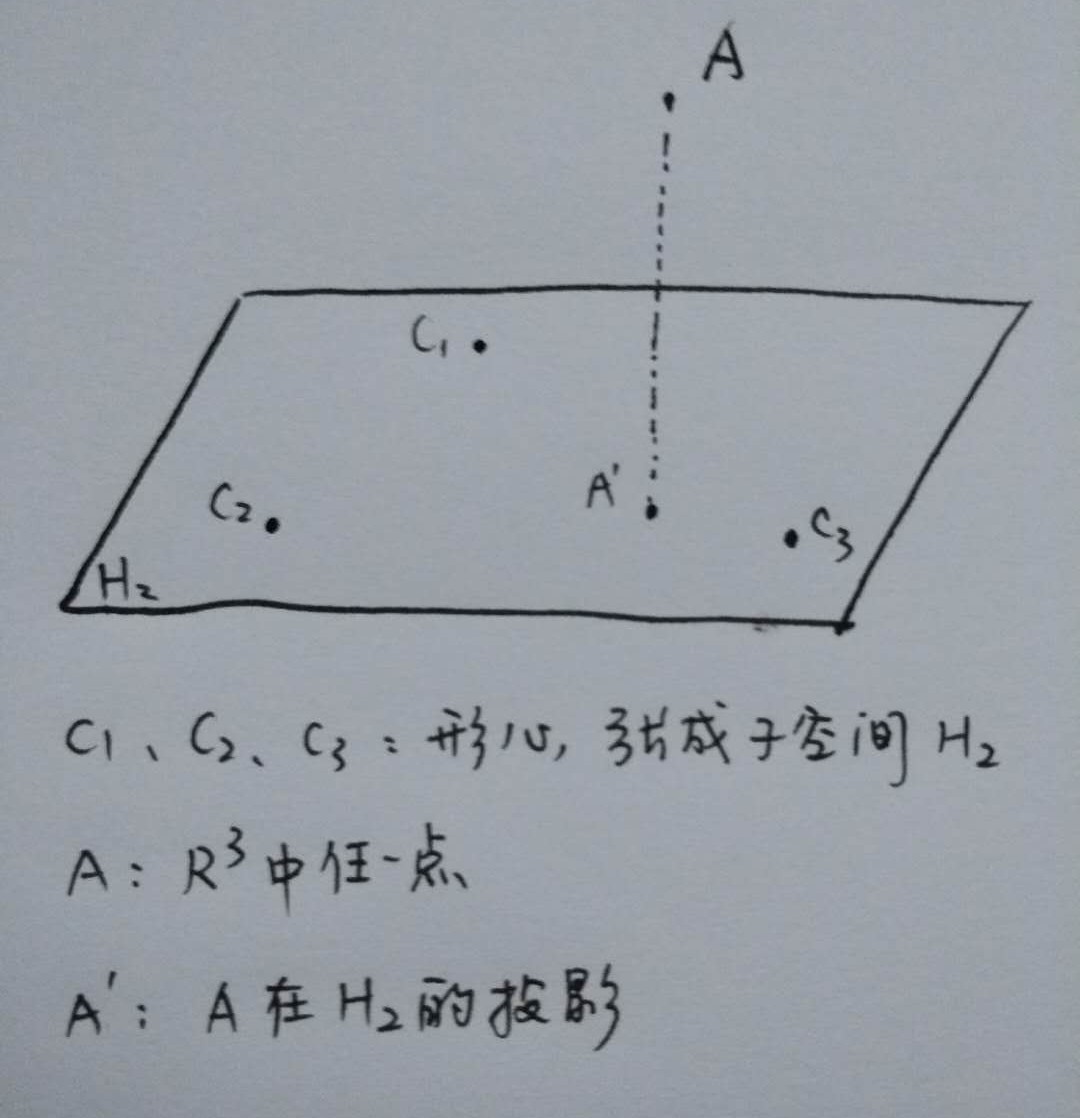 在考虑点 $A$ 的最近形心时,不需要考虑 $A$ 点垂直于 $H_2$ 的距离,也就是直接在 $H_2$ 子空间中比较点 $A$ 在 $H_2$ 中的投影点 $A’$ 与三个待选形心的距离.
在考虑点 $A$ 的最近形心时,不需要考虑 $A$ 点垂直于 $H_2$ 的距离,也就是直接在 $H_2$ 子空间中比较点 $A$ 在 $H_2$ 中的投影点 $A’$ 与三个待选形心的距离.
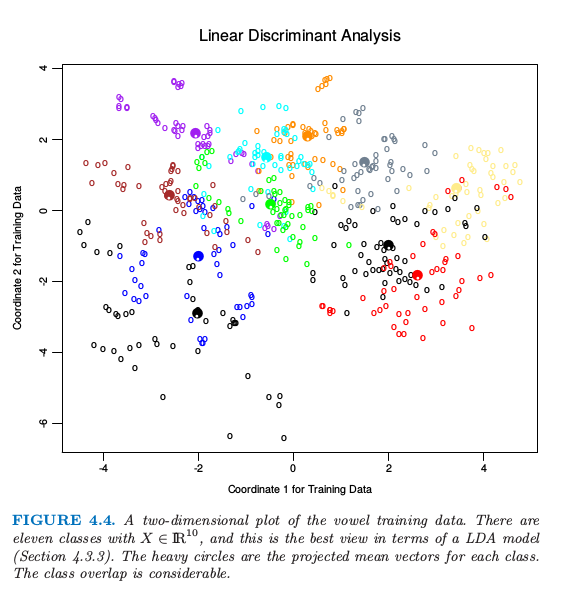
如果 $K > 3$?我们可能在某种意义下要求一个最优的 $L < K-1$ 维子空间 $H_L\subseteq H_{K-1}$.Fisher 定义的最优意思是投影形心关于方差要尽可能地分散.这意味着寻找形心的主成分空间(主成分在 3.5.1 节中有简短的描述,在 14.5.1 节中将详细讨论).图 4.4 显示了对于元音数据的一个最优的二维子空间.这里是一个 $10$ 维的输入空间, 其中有 $11$ 个类别,每一类指不同的元音发音.形心在这种情形下要求全空间,因为 $K-1=p$,但是我们已经展示了一个最优的二维子空间.维数是有序的,所以我们可以依次计算额外的维数.图 4.8 显示了 $4$ 个额外的坐标对,也被称作 典则 (canonical) 或者 判别 (discriminant) 变量.
{kind=link}
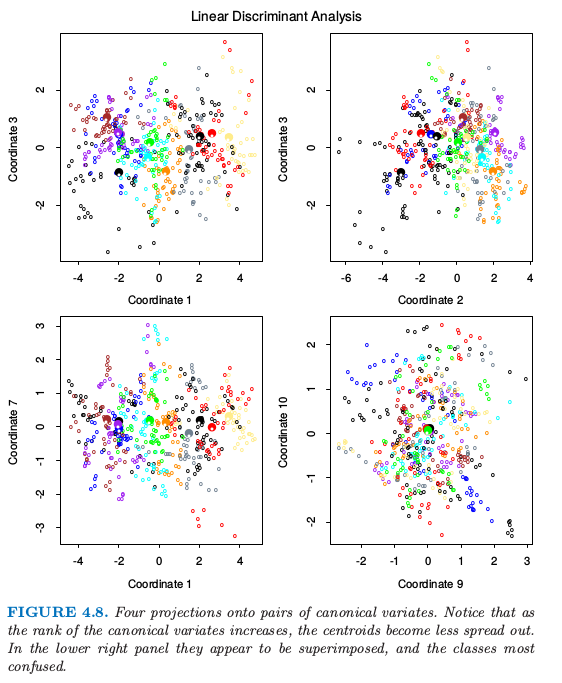
图 4.8. 在成对典则变量上的四个投影.注意到当典则变量的秩增大,形心变得更不发散.右下角的图像看起来像是叠加上去的,类别也更加难以确定.
总结一下,寻找 LDA 的最优子空间序列涉及以下步骤:
- 计算 $K\times p$ 的类别形心矩阵 $\mathbf M$ 以及共同协方差矩阵 $\mathbf W$(组内 (within-class) 协方差)
- 使用 $\mathbf W$ 特征值分解计算 $\mathbf M^*=\mathbf M\mathbf W^{-\frac{1}{2}}$
- 计算 $\mathbf M^*$ 的协方差矩阵 $\mathbf B^*$,($\mathbf B$ 是 组间 (between-class) 协方差),以及特征值分解 $\mathbf B^*=\mathbf V^*\mathbf D_B{\mathbf V^*}^T$.$\mathbf V^*$ 的列 $v_\ell^*$ 从第一个到最后一个依次定义了最优子空间的坐标.
结合上述的操作,第 $\ell$ 个 判别变量 (discriminant variable) 由 $Z_\ell=v_\ell^TX$ 给出,其中 $v_\ell=\W^{-\frac{1}{2}}v_\ell^*$.
weiya 注:
结合 Ex. 4.1 的证明过程来理解上述算法.主要思想是先求 $\mathbf W^{-\frac 12}\mathbf B\mathbf W^{-\frac 12}$ 的特征向量 $v_\ell^*$,则 $\mathbf W^{-1}\mathbf B$ 的特征向量为 $\mathbf W^{-\frac 12}v_\ell^*$.同时注意到我们有 $\Var(v_\ell^TX)=1$ 及 $\Cov(v_\ell^TX,v_k^TX)=0, \ell\neq k$,则判别函数 $\delta_k(z)$ 中的平方和项为 其中 $s$ 为判别变量的个数,$\mu_k[Z_\ell] = v_\ell^T\mu_k$.
Fisher 通过不同的方式得到这个分解,完全没有引用高斯分布.他提出下面的问题:
寻找线性组合 $Z=a^TX$ 使得组间方差相对于组内方差最大化.
再一次,组间方差是 $Z$ 的均值的方差,而组内方差是关于均值的联合方差.图 4.9 显示了为什么这个准则是有意义的.尽管连接形心的方向能将均值尽可能分离开(比如,使得组间方差最大化),但是由于协方差的本性在投影类别上有很大重叠.同时考虑协方差,可以找到最小化重叠的方向.
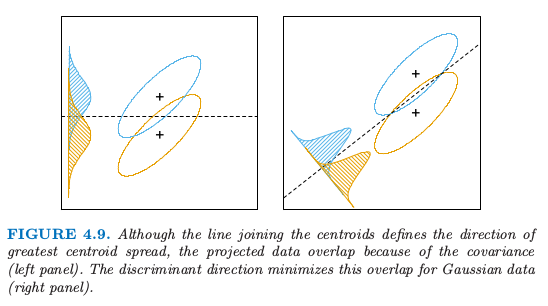
图4.9. 尽管连接形心的直线定义了最大形心分散的方向,但是由于协方差(左图)投影数据会发生重叠.判别边界的方向使得高斯数据的重叠最小(右图).
$Z$ 的组间方差为 $a^T\mathbf Ba$,而组内方差为 $a^T\mathbf Wa$,$\mathbf W$ 是很早定义的,$\mathbf B$ 是类别形心矩阵 $\mathbf M$ 的协方差矩阵.注意到 $\mathbf {B+W=T}$,其中 $\mathbf T$ 是 $\mathbf X$ 的总协方差矩阵,忽略掉了类别信息.
weiya 注:
这里 $\mathbf B$,$\mathbf W$ 和 $\mathbf T$ 均忽略掉了自由度.若有 $N$ 个观测,$K$ 个类别,且 $\bar x_i,\,\bar x,\,\bar x_{ij}$ 均为 $p$ 维向量,则有 它们自由度分别为 $K-1$,$N-K$ 和 $N-1$,易证 $\mathbf{T=B+W}$.
Fisher 问题因此等价于最大化 Rayleigh quotient, 或者等价地, 这是一个一般化的特征值问题,$a$ 是由 $\mathbf W^{-1}\mathbf B$ 的最大特征值给出.不难证明(练习 4.1)最优 $a_1$ 等于上面定义的 $v_1$.类似地,可以找到下一个方向 $a_2$,在 $\mathbf W$ 中与 $a_1$ 正交,使得 $a_2^T{\mathbf B}a_2/a_2^T{\mathbf W}a_2$ 最大化;解为 $a_2=v_2$,其余类似.$a_\ell$ 被称作 判别坐标 (discriminant coordinates),不要与判别函数相混淆.他们也被称作 典则变量 (canonical variables),因为这些结果的一个变形是通过在预测变量矩阵 $\mathbf X$ 上对指示响应矩阵 $\mathbf Y$ 进行典则相关分析得到的.这一点将在 12.5 节继续讨论.
weiya 注:Ex. 4.1
已解决,详见 Issue 142: Ex. 4.1.
总结一下至今为止的发展:
- 有相同的协方差矩阵的高斯分类导出线性判别边界.分类可以通过对数据关于 $\mathbf W$ 球面化得到,并且划分到球空间的最近形心内(矫正因子 $\log\pi_k$)
- 因为只计算了到形心的相对距离,所以可以把数据局限于在球空间的形心张成的子空间.
- 子空间可以进一步分解为关于形心分离的最优子空间.这个分解与 Fisher 的分解相同.
降维后的子空间可以看成是数据降维(为了观察)的一个工具.它们是否可以用于分类以及它的基本原理是什么?很明显它们可以用在分类中,正如我们在最初的变形中一样;我们可以简单地把到形心的距离计算限制到选定的子空间中.可以证明这是有着额外限制条件——高斯形心位于 $\IR^p$ 的 $L$ 维子空间中——的高斯分类器.通过极大似然法拟合这样一个模型,然后运用贝叶斯定理构造后验概率,恰巧是上面描述的分类准则.(练习 4.8)
高斯分类器在距离计算时要求矫正因子 $\log\pi_k$.使用矫正因子的理由可以在图 4.9 中看出.错分类率是基于两个密度计算的重叠部分的面积.如果 $\pi_k$ 是相等的(图中隐含了),则最优的分离点是在投射均值之间.如果 $\pi_k$ 不相等,朝着最小类别移动分类点会改善错误率.正如之前提到的两个类别,可以通过使用 LDA(或者其他任何方法)导出线性规则,然后选择分类点去最小化训练集上的误判率.
作为一个展现降维限制优点的例子,我们回到元音数据.这里有 11 个类别 10 个变量,因此该分类器有 10 个可能的维数.我们可以在每个层次空间计算训练和测试误差;图 4.10 显示了这个结果.图 4.11 显示了基于二维 LDA 的解的分类器的判别边界.
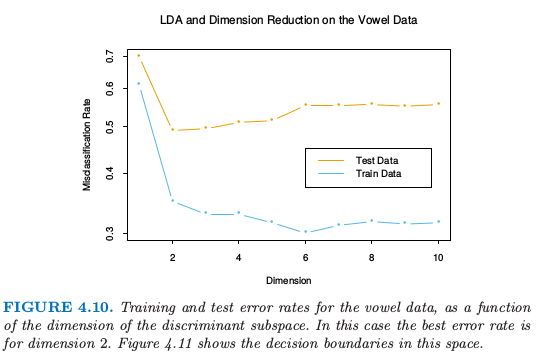
图 4.10. 对于元音数据,训练和测试误差作为判别边界的维数的函数的图象.这种情况下最优的误差率是维数等于 2 的情况.图 4.11 显示了这个空间的判别边界.
Fisher 降秩判别分析 (Reduced-Rank Discriminant Analysis) 和指示响应矩阵回归之间存在着紧密的联系.事实表明 LDA 意味着先回归然后对 $\hat{\mathbf Y}^T\mathbf Y$ 做特征值分解.在两个类的情形下,对于 $\hat{\mathbf Y}$ 的任一列,都存在一个单判别变量,乘上一个标量后能与该列相等.这些联系将在第 12 章中讨论.一个相关的事实是先将原始的预测变量 $\mathbf X$ 转换为 $\hat{\mathbf Y}$,然后用 $\hat{\mathbf Y}$ 做 LDA 与在原空间中做 LDA 是相同的(练习 4.3).
weiya 注:Ex. 4.3
已解决,详见 Issue 144: Ex. 4.3,欢迎讨论交流~
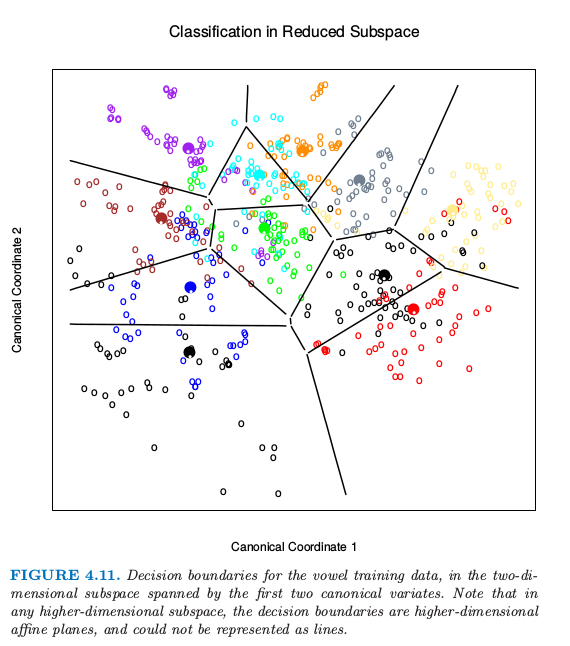
图 4.11. 对于元音训练数据,由前两个典则变量张成的二维子空间中的判别边界.注意到在任何高维子空间下,判别边界是高维仿射平面,而且不可以表示成直线.
-
Hastie, T., Tibshirani, R. and Buja, A. (1994). Flexible discriminant analysis by optimal scoring, Journal of the American Statistical Association 89: 1255–1270. ↩
-
Friedman, J. (1989). Regularized discriminant analysis, Journal of the American Statistical Association 84: 165–175. ↩
-
Michie, D., Spiegelhalter, D. and Taylor, C. (eds) (1994). Machine Learning, Neural and Statistical Classification, Ellis Horwood Series in Artificial Intelligence, Ellis Horwood. ↩